前言
在大量的需求需要进行迭代时,由于时间、人力、财力等相关因素干扰,无法在有限的时间内容对所有的需求进行满足,此时需要我们对需求进行优先级的排列。最大化的合理的提高有限资源的使用。
在常见的产品优先级区分的方式有时间四象限模型和KANO模型。今天主要介绍下KANO模型如何使用。
什么是KANO模型
KANO 模型是东京理工大学教授狩野纪昭(Noriaki Kano)发明的对用户需求分类和优先排序的有用工具,以分析用户需求对用户满意的影响为基础,体现了产品性能和用户满意之间的非线性关系。
根据不同类型的质量特性与顾客满意度之间的关系,狩野教授将产品服务的质量特性分为五类:
基本(必备)型质量——Must-be Quality/ Basic Quality
期望(意愿)型质量——One-dimensional Quality/ Performance Quality
兴奋(魅力)型质量—Attractive Quality/ Excitement Quality
无差异型质量——Indifferent Quality/Neutral Quality
反向(逆向)型质量——Reverse Quality,亦可以将 ‘Quality’ 翻译成“质量”或“品质”
什么是KANO模型来源:百度百科
在产品需求中的KANO模型
参考KANO模型中提出的质量与满意度的关系。将用户需求与用户满意度进行对应的替换。
可以得到以下五类:
基本型需求、期望型需求、兴奋型需求、无差异型需求、反向型需求
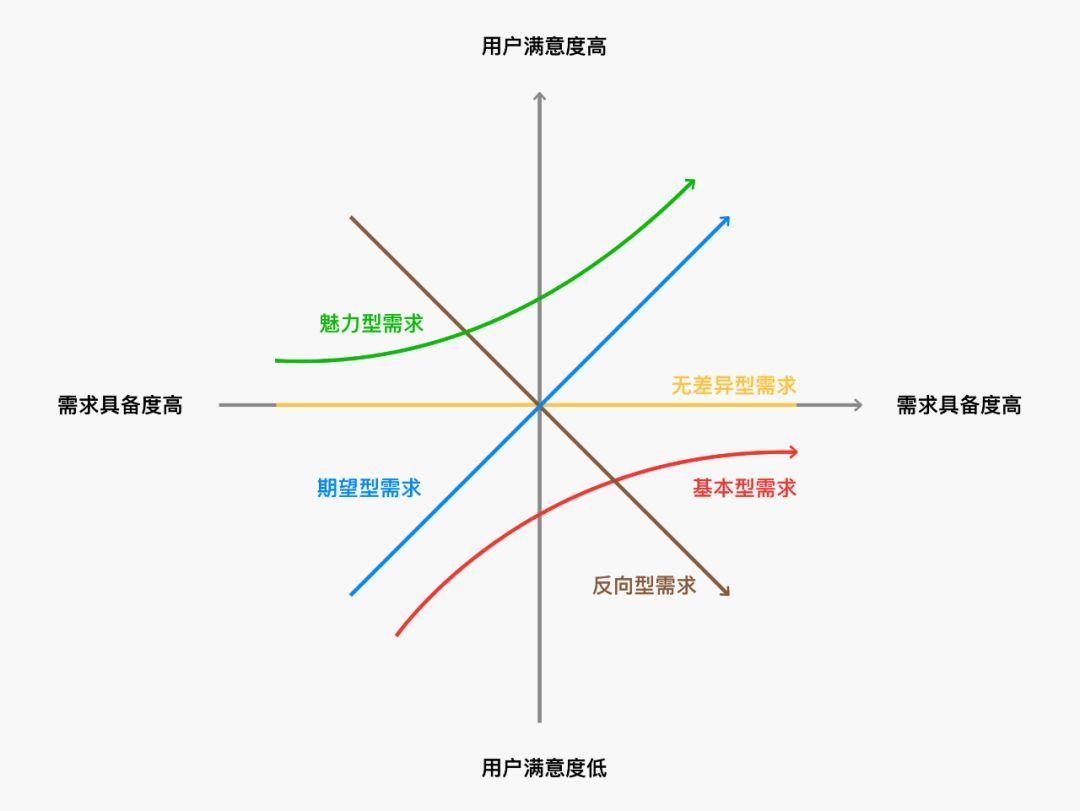
基本型需求
基本型需求,又称必备型需求,是用户对产品的基本需求。
基本型需求存在时不能获得用户太多的好感与满意度,用户理解为你理所应当的提供。但是基本型需求不存在,没有会在用户心中对产品进行大大的折扣。
期望型需求
期望型需求,又称意愿型需求,此类需求与用户满意度成正比,满足用户期望型需求越多,用户满意度越高。
期望型的需求满足用户的类型越多,用户就会逐步的提升对产品的满意度,但满足用户的越少,也会成比例的影响到用户的满意度。
兴奋型需求
兴奋型需求,又称魅力型需求,此类需求,指用户在开始不会有过多的期望,但是如果能够满足用户,便能引起用户的兴奋,从而快速提升用户的满意度。
兴奋型的需求,其实有一种我们经常所说的给人眼前一亮的感觉。这种需求功能能够引起用户的探索性与兴奋性。但是如果不提供,也不会大范围的影响用户满意度。
无差异型需求
无差异型需求,指的是这类需求基本不影响用户满意度,有无即可。此类需求属于边缘需求。
反向型需求
反向型需求,又称逆向型需求。此类需求是和用户满意度背道而驰,实现此功能对用户满意度只有降低。
如何判断需求属于那种类型
在判断需求属于那种类型,一般采用问卷调查的方式进行收集分析。在KNAO模型的调查问卷中,需要对一个问题从正反两个方面进行提问,同时搭配5个层次的选项进行选择。
正反两个方面
“提供”:当产品提供某某功能时。
“不提供”:当产品不提供某某功能时。
注:提供与不提供是两个对立面的设定。可以用其近义词进行对应的代替。如:满足、不满足;有、没有等等。
五个层次
“非常喜欢”:该项要素具备时,会让您感到满意。
“理所当然”:该项要素具备时,您觉得是必须的,必备的。
“无所谓”:该项要素有无对您来说没有差别。
“勉强接受”:该项要素有无,虽然还没到不喜欢的程度,但还可以接受。
“很不喜欢”:该项要素具备时,会让您感到不满意。
问卷设计模式举例
| 问题 | 非常喜欢 | 理所当然 | 无所谓 | 勉强接受 | 很不喜欢 |
|---|---|---|---|---|---|
| 如果我们在应用中提供某某功能,您的评价是? | |||||
| 如果我们在应用中不提供某某功能,您的评价是? |
数据清洗统计
借助调查问卷的收集反馈,过滤掉无效数据(制定过滤无效数据规则,对于部分数据进行舍弃)。然后对数据进行统计。
将统计数据进行汇总到对应的二维表格中。同时参考表格对应的需求类型进行总数的统计。
| 不提供 | ||||||
|---|---|---|---|---|---|---|
| 满意度高 | 满意度较高 | 满意度零 | 满意度较低 | 满意度低 | ||
| 提供 | 满意度高 | |||||
| 满意度较高 | ||||||
| 满意度为零 | ||||||
| 满意度较低 | ||||||
| 满意度低 |
注:类型对应表格(一)(常用类型)
| 不提供 | ||||||
|---|---|---|---|---|---|---|
| 满意度高 | 满意度较高 | 满意度零 | 满意度较低 | 满意度低 | ||
| 提供 | 满意度高 | 可疑结果 | 兴奋型 | 兴奋型 | 兴奋型 | 期望型 |
| 满意度较高 | 反向型 | 无差异型 | 无差异型 | 无差异型 | 必备型 | |
| 满意度为零 | 反向型 | 无差异型 | 无差异型 | 无差异型 | 必备型 | |
| 满意度较低 | 反向型 | 无差异型 | 无差异型 | 无差异型 | 必备型 | |
| 满意度低 | 反向型 | 反向型 | 反向型 | 反向型 | 可疑结果 |
注:类型对应表格(二)
| 不提供 | ||||||
|---|---|---|---|---|---|---|
| 满意度高 | 满意度较高 | 满意度零 | 满意度较低 | 满意度低 | ||
| 提供 | 满意度高 | 可疑结果 | 可疑结果 | 兴奋型 | 期望型 | 期望型 |
| 满意度较高 | 可疑结果 | 可疑结果 | 兴奋型 | 期望型 | 必备型 | |
| 满意度为零 | 反向型 | 反向型 | 无差异型 | 必备型 | 必备型 | |
| 满意度较低 | 反向型 | 反向型 | 反向型 | 可疑结果 | 可疑结果 | |
| 满意度低 | 反向型 | 反向型 | 反向型 | 可疑结果 | 可疑结果 |
如何选择对应的分析模型,要结合实际情况进行处理。
常见的影响因素:需求可能会因人而异、需求可能因文化差异而不同、需求会随时间变化等。
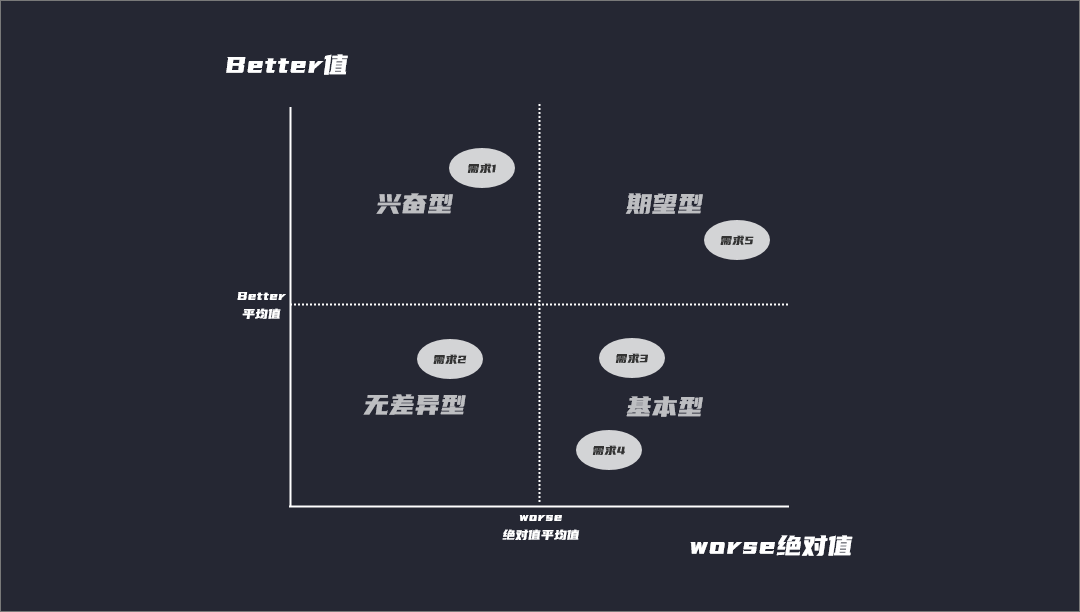
Better-Worse系数分析
在处理完成对应的需求数量统计后。我们就将需求进行Better-Worse系数分析。
Better,可以解读为增加后的满意系数。 Better的数值通常为正,代表如果产品提供某种功能或服务,用户满意度会提升。正值越大/越接近1,则表示用户满意度提升的效果会越强,满意度上升的越快。

Worse,可以叫做消除后的不满意系数。 Worse的数值通常为负,代表产品如果不提供某种功能或服务,用户的满意度会降低。其负值越大/越接近-1,则表示对用户不满意度的影响最大,满意度降低的影响效果越强,下降的越快。

根据对应计算出的系数,我们对应的需求进行四象限的划分。从而得出需求的所属类型。
如何需求排序、如何处理
类型顺序
对于分析的统计结果,按照对应的类型将需求进行分类。
基本型需求 > 期望型需求 > 兴奋型需求 > 无差异需求
实际中需求类型如何理解,如何处理
在实际中,如果资源充沛的情况下可以按照按照保证基本型需求满足,提高期望型需求,扩展兴奋型需求的逻辑进行对应需求的处理。
如果在资源有限的情况下,则进行逐级递减。在递减的同时,可以针对每种类型进行优先级的排列。
同时也要结合实际的业务以及战略进行优先级的调整处理。例如:产品某些商业化的需求本身就是一个反向型的需求,例如:广告,但是为了平衡商业化,这些都是需要去考虑在内的。只不过是尽可能减少对应的影响。
模型不足和实际使用
KANO模型虽然在需求调研阶段中可以对需求进行优先级的分类,但是相对操作比较复杂,针对差异性较大的可以进行有效的区分,但是对于差异性较小的进行区分可能效果不佳。同时通过KANO进行文件调查,若需求较多,可能问卷题量较多,最终导致问卷数据价值偏低。所以在使用KANO模型时,首先需要对需要做一个初步的筛选,然后进行对应的问卷投放调研。
总结
在学习KANO模型如何搭建,会进行对应的数据输出。同时要有自我对结果的认知与判断。总的一句话,所有的模型数据,所有的调研数据都是为我们最终的决策提供辅助作用。在实际中要充分结合场景、资源进行合理规划。




